
ChatGPT-4Vision(GPT-4V)には、画像入力が可能であり、それを説明する画像認識機能が搭載されています。本記事では、GPT-4Vを実際に使ってレビューします。



ChatGPT-4Vに日本語の画像を入力して画像認識させてみた
ChatGPT-4V(GPT-4V)に、日本語で作られたサムネイル画像を入力すると、どのような認識結果になるのか試してみます!
下記手順に従って、画像認識を行いました。
- OpenAIのChatGPT-4V(ision)を開く
- 入力で画像ファイルを選択する
- 目的をGPT-4V(ision)に入力する
- 画像認識の結果を確認する
OpenAIのChatGPT-4V(ison)を開く
まずは、OpenAIにアクセスし、ChatGPT Plusに契約したあと、GPT-4V(ison)の画面を開きます。
GPT-4V(ison)に関する詳細な説明は、公式サイトをご覧下さい。(GPT-4の画面で問題ありません。)
入力で画像ファイルを選択する
入力で画像ファイルを選択します。今回は、ChatGPT-4V(ision)が日本語の文字の意味も理解できるのか検証するために、日本語で書かれたサムネイル画像を選択します。
目的をGPT-4V(ision)に入力する
目的をGPT-4V(ision)に文章で入力します。
今回は、「この画像について説明してください。」をGPT-4V(ision)に入力して、送信します。
画像認識の結果を確認する
-1024x538.jpg)
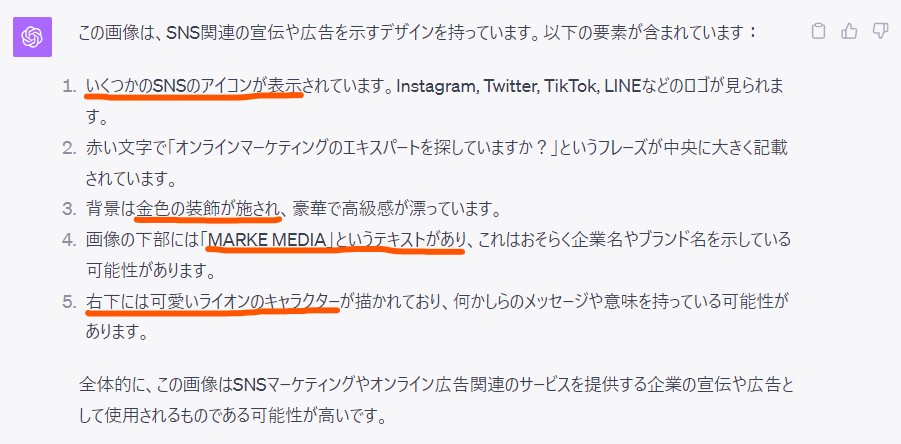
結果として、5行で説明文が表示され、ChatGPTのGPT-4V(ision)では、日本語のサムネイル画像でも高度な画像認識機能が備わっているようです。
良かった点
悪かった点
記事を読んでいる方におすすめの資料はこちらにまとめています。

DALL・E 3で画像生成するためにGPT-4Vを活用してみた
ChatGPTのGPT-4にて、DALL・E 3が使えるようになりました。しかし、どのような画像を生成したいのか文章を入力する必要があります。
先ほど、GPT-4V(ision)を使うと、画像認識を行い、どのような画像か回答をもらえたので、DALL・E 3にも使えないか試してみました。
結果的に、
下記の手順にて進めます。
- GPT-4V(ision)で画像の特徴を説明してもらう
- DeepLを使って文章を翻訳する
- ChatGPT(GPT-4)のDALL・E 3に入力する
GPT-4V(ision)で画像の特徴を説明してもらう
もうそろそろ日本では紅葉の季節ですので、下記画像を用意しました。
さっそく、GPT-4V(ision)に画像を認識させて、特徴を説明してもらいましょう!
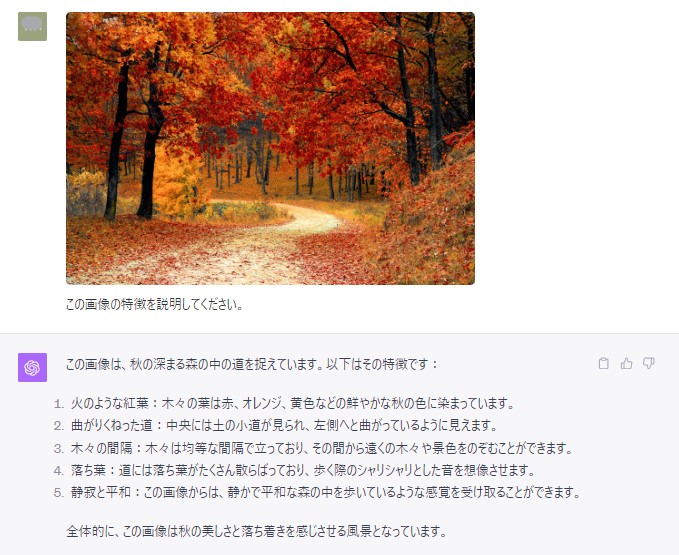
画像を見てみると、ここにテントを置きたいと思ったので、下記の画像も認識させてみます。
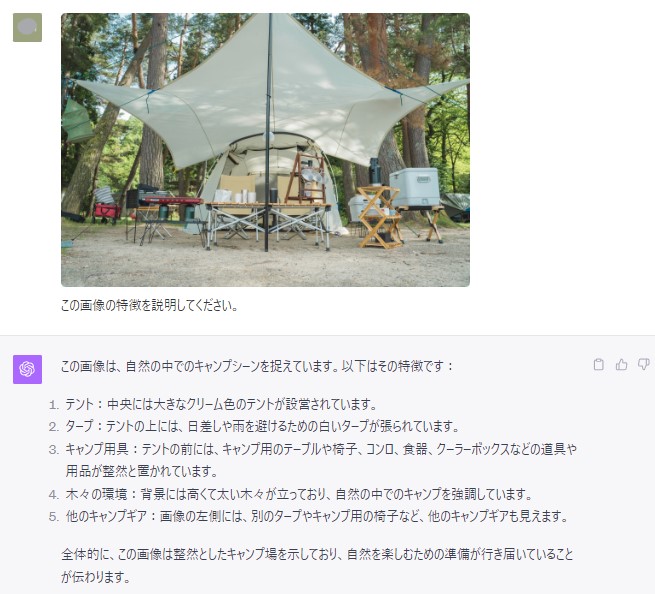
2つの画像を認識させ、特徴を説明してもらったので、準備は完了です。
DeepLを使って文章を翻訳する

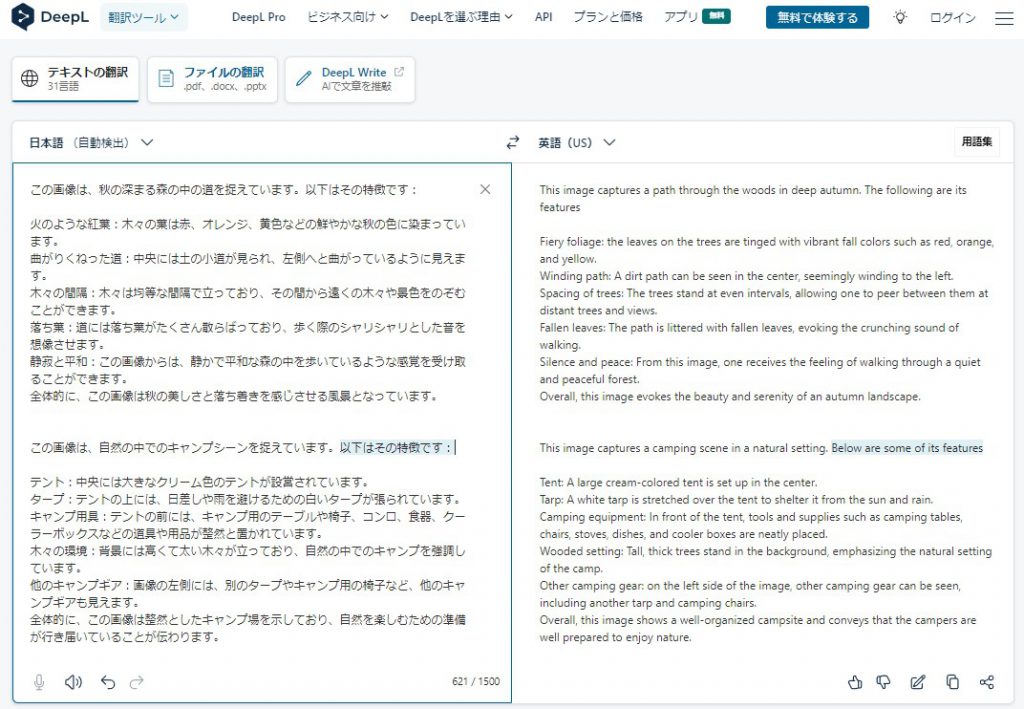
翻訳ができたら、自分が必要と思う英文だけ抽出して、GPT-4のDALLE-3に貼り付けるために、コピーします。
ChatGPT(GPT-4)のDALL・E 3に入力する
ChatGPTのGPT-4で「DALL・E 3」を選択します。
2つの画像の特徴を英文で必要だと思う英文箇所のみ貼り付けます。
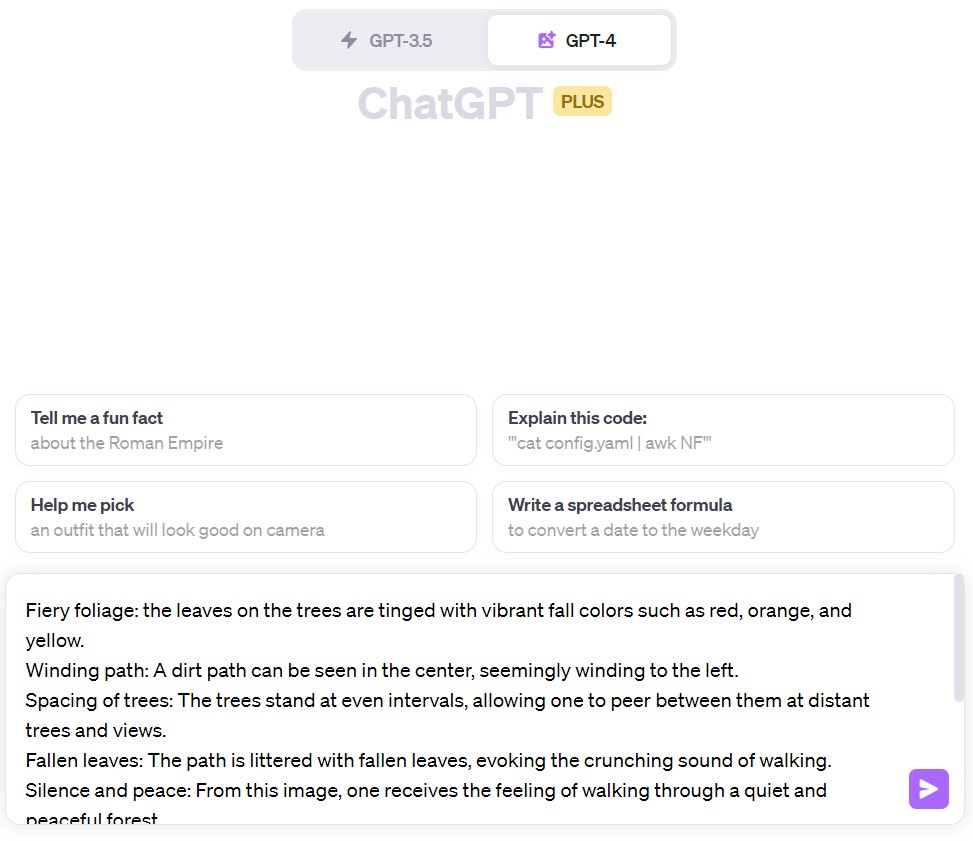
出力してみました。
入力内容

出力結果

2つに分けられて出力されてしまったため、改行をせず、「全体的に~」の文言を文末に移動させ、少し文言を変更して再出力します。
再出力結果

秋の紅葉の存在感が薄くなりましたが、完成しました!
今回、DALL・E 3で生成された画像は、思ったものと少し異なったので、入力文が不足していたようです。しかし、入力文次第で思ったとおりの画像を生成できると思います。
まとめ
本記事では、ChatGPTのGPT-4V(ision)を使って、日本語のサムネイル画像を入力をして画像認識をさせてみました。結果として高度な画像解析技術が備わっており、思った以上に正確に画像についての説明が出力されました。
ChatGPTのGPT-4に追加されたDALL・E 3も使ってみましたが、テキストだけで画像を生成することができ、入力文次第で意図どおりの画像を生成することができます。
今回の記事はいかがだったでしょうか。私のように作ってみた画像などがあれば、コメントをお待ちしております!



コメント